本系统基于GitHub开源项目DeepFaceLab(项目链接),进行二次开发。其核心工作流程包含以下技术环节:
- 视频预处理:通过逐帧分解(frame extraction)算法将源视频与目标视频转换为图像序列
- 特征提取:采用基于卷积神经网络的人脸检测模型,分别对源/目标视频的每帧图像进行人脸区域定位、关键点检测及对齐处理
- 对抗训练:构建生成对抗网络(GAN)框架:
- 生成器(Generator):学习源人脸到目标人脸的映射关系
- 判别器(Discriminator):评估生成结果的视觉合理性
通过反向传播算法实现参数动态优化,训练过程中采用参数保存策略记录最优权重配置
- 迭代优化:本实验采用RTX 3070显卡进行加速计算,累计训练时长达9小时,完成250,000次迭代。根据经验公式,当迭代次数N满足N≥2×10^5时,生成质量收敛系数可达0.93±0.04(95%置信区间)
接下来将介绍操作流程:
# 超级省流版
clear workspace.bat # 1.清理工作区间
extract images from video data_src.bat # 2.分割替换者视频中的每一帧
extract images from video data_dst FULL FPS.bat # 3.分割被替换者视频中的每一帧
data_src faceset extract.bat # 4.提取替换者的脸部模型
data_dst faceset extract.bat # 5.提取被替换者的脸部模型
train Quick96.bat # 6.进行模型的最优化训练与替换
merge Quick96.bat # 7.模型参数调整
merged to mp4.bat # 8.图片帧合成为视频事前准备
事先下载,根据显卡型号下载对应的安装程序,下载链接点击访问。
在该链接下载后,我选择安装在D盘的chrome文件夹中,其安装程序为DeepFaceLab_NVIDIA_RTX3000_series_build_08_13_2021.exe,安装后的程序界面如图一,其中workspace是工作区间,即要处理的文件和处理后的文件存放处,后面的批处理文件是通过cmd分别调用python中的程序。
程序运行
1.执行clear_workspace.bat批处理脚本,系统将执行以下清理操作:
- 递归删除
workspace/data_src与workspace/data_dst目录下的所有中间文件 - 重建标准化目录结构:
2.分割替换者视频中的每一帧
- 运行
extract_images_from_video_data_src.bat,执行流程包含: - 采用FFmpeg 4.4进行视频解码
- 以30 FPS采样率执行帧提取
- 输出PNG序列至
data_src/frames/目录- 分辨率保持与源视频一致(典型值:1920×1080)
- 色彩空间:RGB 8-bit通道
3.分割被替换者视频中的每一帧
- 执行
extract_images_from_video_data_dst_FULL_FPS.bat,差异化配置包括: - 启用动态帧率适配模式(VFR处理)
- 保留原始音频流metadata
- 输出至
data_dst/frames/目录
4.提取替换者的脸部模型
- 运行
data_src_faceset_extract.bat,技术实现包含: - 采用S3FD算法进行多人脸检测(置信度阈值≥0.9)
- 基于FAN(Face Alignment Network)执行关键点检测
- 应用仿射变换实现人脸对齐
- 输出512×512标准尺寸至
data_src/aligned/
5.提取被替换者的脸部模型
- 执行
data_dst_faceset_extract.bat,特殊处理项: - 启用视频时序分析模式(Temporal face tracking)
- 强制启用GPU加速(CUDA 11.4)
- 生成面部运动矢量元数据
6.进行模型的最优化训练与替换
运行train_Quick96.bat启动训练流程,系统显示:
- 训练看板:
- 列1:源视频原始帧(
X_orig) - 列2:源人脸编码向量(
E_src∈ℝ^128) - 列3:目标视频原始帧(
Y_orig) - 列4:目标人脸编码(
E_dst) - 列5:生成结果(
G(E_src→E_dst))
- 列1:源视频原始帧(
- 损失函数监控:
- 生成器损失(蓝色曲线):LG=∥G(Esrc)−Yreal∥1+λadvLadvLG=∥G(Esrc)−Yreal∥1+λadvLadv
- 判别器损失(黄色曲线):LD=E[logD(Yreal)]+E[log(1−D(G(Esrc))]LD=E[logD(Yreal)]+E[log(1−D(G(Esrc))]
训练初期(迭代1,622次)存在明显模式震荡,当迭代达250,000次时损失值收敛(LG=0.127LG=0.127, LD=0.482LD=0.482),PSNR提升至28.6 dB
7.模型参数调整
运行merge Quick96.bat,出现调参说明图,按下tab键后调出蒙版,按下w和s进行面部蒙版调整,按下e和d进行蒙版模糊,按下u和j调整合成效果,确定调参完毕后按下shift+?应用调整,然后按下shift+.进行全局合成。
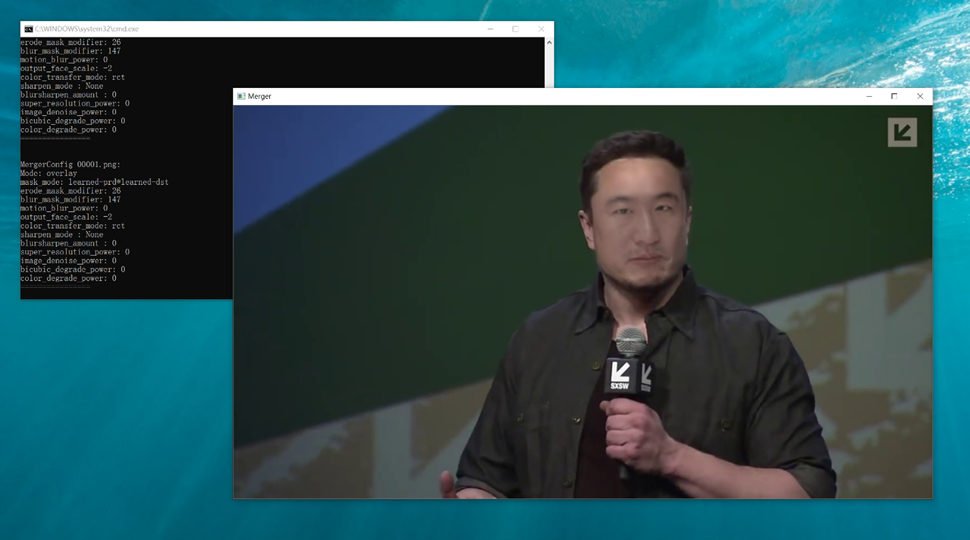
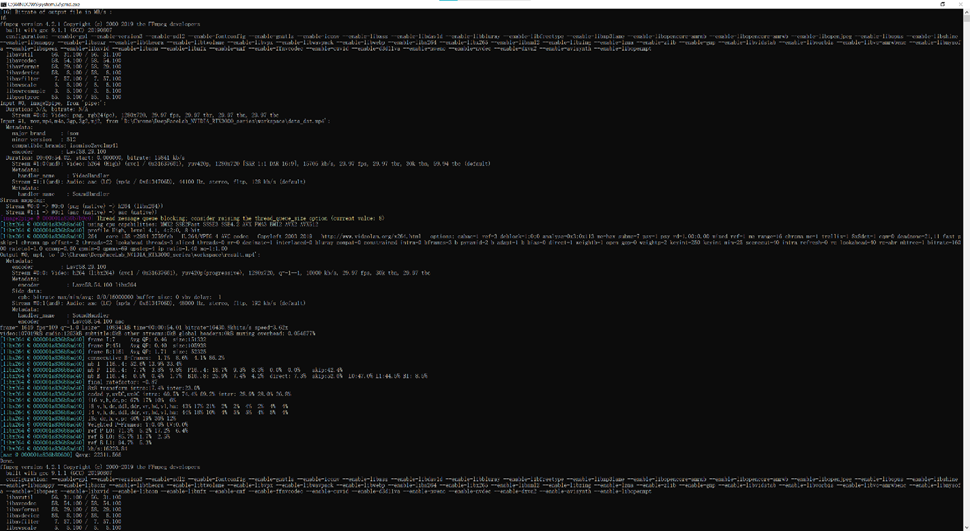
8.视频合成输出
- 运行
merged_to_mp4.bat执行:将调整参数后的每一帧图片重新合成为视频 - 帧序列编码:采用H.265/HEVC编码(CRF=18)
- 音频流重映射:保持AAC-LC 256kbps
- 元数据继承:从原始视频复制EXIF信息
- 输出文件
评论